 { const baseUrl = "https://www.google.co.il/search?q=site:forum.otzaria.org"; const m = location.pathname.match(/^\/(topic|category)\/(\d+)/); const type = m ? m[1] : null; const id = m ? m[2] : null; let searchInput; function search(path = "") { const query = searchInput.value.trim(); if (query) { window.open(`${baseUrl}${path}%20${encodeURIComponent(query)}`, "_blank"); } } let buttons = {}; buttons.searchAll = { id: "bb-search-all", label: `חיפוש ${type ? "בכל הפורום" : ""}`, className: type ? "btn-secondary" : "btn-primary", callback: () => search(), }; if (type === "topic") { buttons.searchTopic = { label: "חיפוש בנושא זה", className: "btn-primary", callback: () => search(`/topic/${id}`), }; } else if (type === "category") { buttons.searchCategory = { label: "חיפוש בקטגוריה זו", className: "btn-primary", callback: () => search(`/category/${id}`), }; } buttons.cancel = { label: "ביטול", className: "btn-default", "data-bs-dismiss": "modal" }; const dialog = bootbox.dialog({ title: '<div style="display:flex; align-items:center; justify-content:center; gap:15px;"><img src="https://forum.otzaria.org/assets/uploads/system/site-logo.png?v=4921ea700b3" width="60" alt="פורום אוצריא"><span style="font-size:24px; font-weight:bold;">פורום אוצריא</span></div>', message: '<input id="bb-inp" class="bootbox-input bootbox-input-text form-control" placeholder="הקלידו כדי לחפש בגוגל" autocomplete="off"/>', buttons, backdrop: true, show: true, onEscape: true }); dialog.on("shown.bs.modal", function () { searchInput = document.getElementById("bb-inp"); if (searchInput) { searchInput.focus(); searchInput.addEventListener("keydown", function (e) { if (e.key === "Enter") { e.preventDefault(); const query = this.value.trim(); if (query) { search(); dialog.modal("hide"); } } else if (e.key === "Escape") { e.preventDefault(); dialog.modal("hide"); } }); } const searchAllButton = document.getElementById("bb-search-all"); if (searchAllButton) { searchAllButton.title = "לחצו על אנטר כדי לחפש"; } }); })(); void 0;){kind=link}
מדריך | יצירת קטלוג של הספרים באוצריא
-
כמדומני שאין קטלוג מסודר של הספרים באוצריא.
באחד הפוסטים נכתב על קובץ SourcesBooks.CSV שמכיל את הרשימה. שזו אותה רשימה שנמצאת במסך הספריה.
החיסרון הוא למי שרוצה לראות בסקירה את כל הספרים יחד, בלי לפתוח תקיה תקיה, ומצד שני בלי כפילות (לוגית) מיותרת כמו שמופיע חידושי הרן על כל מסכת (רן על ברכות ורן על מגילה). כי בסוף רוצים לראות את שמות הספרים ולא כמה חלקים יש מכל ספר.
הפתרון שכרגע מצאתי, הוא סינון של הרשימה באקסל.
מצורף דוגמא לסינון שעשיתי:
הסברים:
בתוכנת אקסל > נתונים > מCSV ולפתוח בתוך תקית אוצריא את תקית אודות ולפתוח את קובץ SourcesBooks.
לטעון את הנתונים.
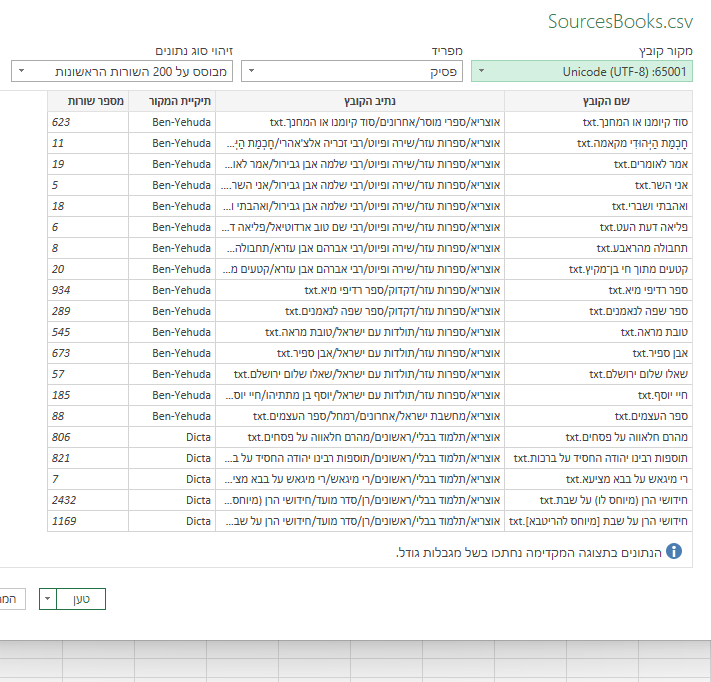
לעמוד על התא החדש שבשורה הראשונה משמאל לטבלה, והזין את הפונקציה הזאת ולאשר.
=TRIM(LEFT(A2, IFERROR(FIND(" על ", A2), LEN(A2)+1)-1))
תווצר אוטומטית עמודה חדשה על כל הטבלה.
עכשיו ניתן ללחוץ על הסר כפילות.ואם נשנה את המילה על שבפונקציה לרשימה הזאת ונסיר כפילות כל פעם, נשאר רק עם הרשימה האמיתית.
על, חלק, שולחן, וכדו'הפונקציה חותכת את שאר התא כך שאפשר לצמצם בקלות את הרשימה.
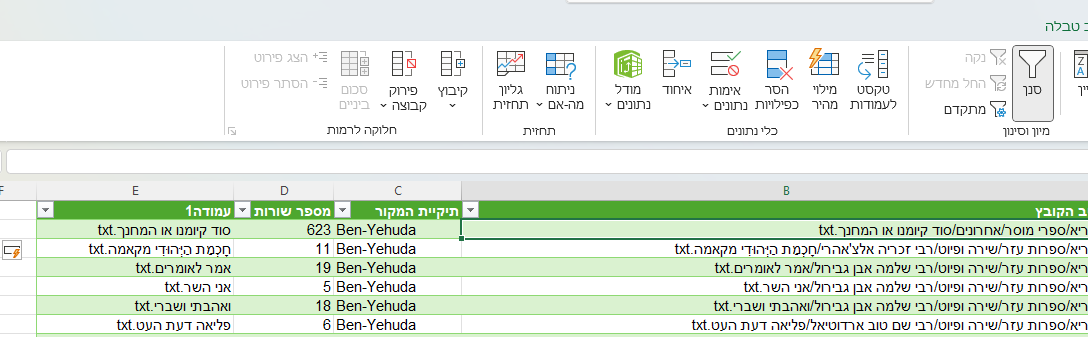
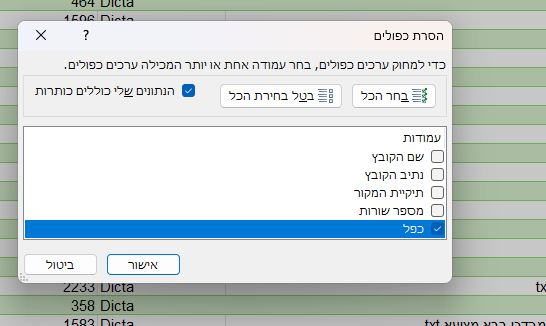
רק חשוב לציין שצריך להסיר רק כפילות של העמודה החדשה שהיא זו שמסננת, ולא למשל את המספרי שורה שאולי יש 2 ספרים עם אותו מספר שורות.
כמובן שזה אקסל וניתן למיין ולהדפיס.מסתבר שמישהו יכול פשוט ליצור תוכנה קטנה. אבל בינתיים זה מאפשר סקירה מהירה על כל המאגר.
ושוב הרשימה: חוברת1.xlsx
-
כמדומני שאין קטלוג מסודר של הספרים באוצריא.
באחד הפוסטים נכתב על קובץ SourcesBooks.CSV שמכיל את הרשימה. שזו אותה רשימה שנמצאת במסך הספריה.
החיסרון הוא למי שרוצה לראות בסקירה את כל הספרים יחד, בלי לפתוח תקיה תקיה, ומצד שני בלי כפילות (לוגית) מיותרת כמו שמופיע חידושי הרן על כל מסכת (רן על ברכות ורן על מגילה). כי בסוף רוצים לראות את שמות הספרים ולא כמה חלקים יש מכל ספר.
הפתרון שכרגע מצאתי, הוא סינון של הרשימה באקסל.
מצורף דוגמא לסינון שעשיתי:
הסברים:
בתוכנת אקסל > נתונים > מCSV ולפתוח בתוך תקית אוצריא את תקית אודות ולפתוח את קובץ SourcesBooks.
לטעון את הנתונים.
לעמוד על התא החדש שבשורה הראשונה משמאל לטבלה, והזין את הפונקציה הזאת ולאשר.
=TRIM(LEFT(A2, IFERROR(FIND(" על ", A2), LEN(A2)+1)-1))תווצר אוטומטית עמודה חדשה על כל הטבלה.
עכשיו ניתן ללחוץ על הסר כפילות.ואם נשנה את המילה על שבפונקציה לרשימה הזאת ונסיר כפילות כל פעם, נשאר רק עם הרשימה האמיתית.
על, חלק, שולחן, וכדו'הפונקציה חותכת את שאר התא כך שאפשר לצמצם בקלות את הרשימה.
רק חשוב לציין שצריך להסיר רק כפילות של העמודה החדשה שהיא זו שמסננת, ולא למשל את המספרי שורה שאולי יש 2 ספרים עם אותו מספר שורות.
כמובן שזה אקסל וניתן למיין ולהדפיס.מסתבר שמישהו יכול פשוט ליצור תוכנה קטנה. אבל בינתיים זה מאפשר סקירה מהירה על כל המאגר.
ושוב הרשימה: חוברת1.xlsx
-
@מעמע יש לך טעות גדולה. אין שום כפילויות בספרים.
אני ממש לא מבין על איזה כפילויות אתה מדבר!!!
אשמח שתכתוב כאן אפילו כפילות אחד שמצאת! -
@מעמע יש לך טעות גדולה. אין שום כפילויות בספרים.
אני ממש לא מבין על איזה כפילויות אתה מדבר!!!
אשמח שתכתוב כאן אפילו כפילות אחד שמצאת!@יום-חדש-מתחיל הוא מדבר על "חידושי הרן על בבא קמא" ו"חידושי הרן על בבא מציעא", לא על ספר שיש אותו פעמיים.
-
@יום-חדש-מתחיל הוא מדבר על "חידושי הרן על בבא קמא" ו"חידושי הרן על בבא מציעא", לא על ספר שיש אותו פעמיים.
@הבל-הבלים נכון. אני התכוונתי לכפילות לוגית, שרוצים את שם הספר עצמו ולא את הכרכים שיש לכל ספר, כמו חלק א חלק ב.
עדכנתי את הפוסט הראשון, וגם צירפתי דוגמא שסיננתי.
-
מצורף קוד פייתון שעושה את העבודה - וגם קוד מקומפל לתוכנה.
הקוד יוצר קובץ אקסל עם עמודות מסודרות - של שם הספר והנתיב שלו.
הוא מסיר כפילויות של:
" על ", " חלק ", " שולחן ", "-", "מסכת"אם אתם רוצים להוסיף כפילויות נוספות - פשוט תכניסו אותם לקובץ cut_words.json המצורף.
(-גם בלי הקובץ הנ"ל הקוד מסיר בכל מקרה את הכפילויות הנ"ל)import os import sys import json import csv import tkinter as tk from tkinter import filedialog, messagebox from openpyxl import Workbook from openpyxl.worksheet.table import Table, TableStyleInfo # ================================================== # הגדרות # ================================================== DEFAULT_PATH = r"C:\אוצריא\אוצריא\אודות התוכנה\SourcesBooks.csv" REQUIRED_NAME = "SourcesBooks.csv" CONFIG_PATH = os.path.join(os.getenv("APPDATA", os.getcwd()), "sourcesbooks_config.json") OUTPUT_XLSX = os.path.join(os.path.expanduser("~"), "Desktop", "רשימת_ספרים.xlsx") # שמירה על שולחן העבודה # טען רשימת חיתוך חיצונית (אפשר לערוך cut_words.json) CUT_WORDS_FILE = "cut_words.json" if os.path.isfile(CUT_WORDS_FILE): with open(CUT_WORDS_FILE, encoding="utf-8") as f: data = json.load(f) CUT_WORDS = data.get("cut_words", []) else: # ברירת מחדל אם אין קובץ חיצוני CUT_WORDS = [" על ", " חלק ", " שולחן ", "-", "מסכת"] # ================================================== # איתור הקובץ # ================================================== def load_saved_path(): if os.path.isfile(CONFIG_PATH): try: with open(CONFIG_PATH, encoding="utf-8") as f: data = json.load(f) path = data.get("path") if path and os.path.isfile(path): return path except Exception: pass return None def save_path(path): os.makedirs(os.path.dirname(CONFIG_PATH), exist_ok=True) with open(CONFIG_PATH, "w", encoding="utf-8") as f: json.dump({"path": path}, f, ensure_ascii=False, indent=2) def choose_file(): root = tk.Tk() root.withdraw() messagebox.showinfo( "בחירת קובץ", f'הקובץ "{REQUIRED_NAME}" לא נמצא.\n\n' f'אנא נווט לקובץ בשם "{REQUIRED_NAME}"' ) while True: path = filedialog.askopenfilename( title=f'בחר את הקובץ "{REQUIRED_NAME}"', filetypes=[("CSV files", "*.csv"), ("All files", "*.*")] ) if not path: messagebox.showerror("בוטל", "לא נבחר קובץ. התוכנית תיסגר.") sys.exit(1) if os.path.basename(path) != REQUIRED_NAME: messagebox.showerror("שם קובץ שגוי", f"נדרש לבחור קובץ בשם:\n{REQUIRED_NAME}") continue return path def locate_sourcesbooks(): if os.path.isfile(DEFAULT_PATH): save_path(DEFAULT_PATH) return DEFAULT_PATH saved = load_saved_path() if saved: return saved chosen = choose_file() save_path(chosen) return chosen # ================================================== # ניקוי שם ספר לפי CUT_WORDS + מסכת + "-" # ================================================== def clean_title(title: str) -> str: t = title # חיתוך לפי CUT_WORDS first_idx = len(t) for w in CUT_WORDS: idx = t.find(w) if idx != -1 and idx < first_idx: first_idx = idx t = t[:first_idx].strip() # חיתוך לפי "מסכת" אם היא מופיעה כמילה שלישית words_after_cut = t.split() if len(words_after_cut) >= 3 and "מסכת" in CUT_WORDS and words_after_cut[2] == "מסכת": t = " ".join(words_after_cut[:2]).strip() return t # ================================================== # קריאה וייצוא לאקסל (בלי טור מקור הקובץ) # ================================================== def export_to_excel(csv_path): books_set = set() books_list = [] with open(csv_path, encoding="utf-8", newline="") as f: reader = csv.reader(f) for row in reader: if not row: continue raw = row[0].strip() if raw: clean_name = clean_title(raw) if clean_name not in books_set: books_set.add(clean_name) books_list.append({ "name": clean_name, "file_path": os.path.dirname(csv_path) }) books_list.sort(key=lambda x: x["name"]) wb = Workbook() ws = wb.active ws.title = "ספרים" # הגדרת כיוון מימין לשמאל ws.sheet_view.rightToLeft = True # כותרות ws.append(["מספר", "שם הספר", "נתיב הקובץ"]) for i, book in enumerate(books_list, start=1): ws.append([i, book["name"], book["file_path"]]) table = Table(displayName="BooksTable", ref=f"A1:C{len(books_list)+1}") style = TableStyleInfo( name="TableStyleMedium9", showFirstColumn=False, showLastColumn=False, showRowStripes=True, showColumnStripes=False ) table.tableStyleInfo = style ws.add_table(table) # רוחב עמודות מותאם ws.column_dimensions["A"].width = 8 ws.column_dimensions["B"].width = 55 ws.column_dimensions["C"].width = 80 wb.save(OUTPUT_XLSX) # ================================================== # MAIN # ================================================== if __name__ == "__main__": sourcesbooks_path = locate_sourcesbooks() print("✔ נמצא הקובץ:", sourcesbooks_path) export_to_excel(sourcesbooks_path) print(f"✔ נוצר קובץ אקסל: {OUTPUT_XLSX}") input("\nסיום – לחץ Enter כדי לצאת")הנה הקוד פייתון להורדה:
ExportBooks.PYוהנה כתוכנה:
ExportBooks.exeוהנה - הקובץ אקסל שנוצר - "רשימת ספרים" בשולחן העבודה.
רשימת_ספרים.xlsx